تحلیل دادههای حجیم(Big Data): معرفی بهترین ابزارهای تجزیه و تحلیل

در قسمتهای قبلی از مجموعه مقالات "کلان داده"، به بررسی "مفاهیم کلان داده و انواع تحلیل داده" و "تحلیل کلان داده، چالشها و فناوریهای مرتبط" پرداخته شد. در این بخش، به بررسی ابزارهای تحلیل کلان داده و مسائل مرتبط با آن میپردازیم، از جمله:
-
آپاچی هادوپ (Apache Hadoop):
- یک فریمورک متنباز برای پردازش و ذخیرهسازی دادههای حجیم.
- معماری اصلی شامل الگوریتم نگاشت کاهش (MapReduce) است که به توزیع بهینهی دادهها بر روی گرههای مختلف سرورها میپردازد.
-
الگوریتم نگاشت کاهش (MapReduce):
- یک الگوریتم برنامهنویسی موازی برای پردازش همزمان دادههای بزرگ.
- استفاده از توابع Map و Reduce برای تقسیم و ادغام دادهها.
-
سیستم فایل توزیع شده هادوپ (Hadoop Distributed File System | HDFS):
- سیستم فایلی که برای ذخیرهسازی دادههای حجیم و توزیع شده در سرورهای مختلف استفاده میشود.
-
آپاچی هایو (Apache Hive):
- یک ساختار استفاده از زبان پرس و جو برای استفاده آسانتر از دادههای ذخیرهشده در هادوپ.
-
آپاچی ماهوت (Apache Mahout):
- یک کتابخانه متنباز برای یادگیری ماشین و ایجاد الگوریتمهای هوش مصنوعی.
-
آپاچی اسپارک (Apache Spark):
- یک فریمورک پردازش دادههای موازی و سریع با استفاده از مفهوم اشتراکگذاری داده در حافظه.
-
دریاد (Dryad):
- یک فریمورک پردازش دادههای موازی از مایکروسافت.
-
استورم (Storm):
- یک سیستم پردازش دادههای جریانی (stream processing) برای پردازش لحظهای دادهها.
-
آپاچی دریل (Apache Drill):
- یک موتور پرس و جوی توزیع شده برای پرس و جوی دادههای ساختاری و ناهیکل.
-
جاسپرسافت (Jaspersoft):
- یک سیستم گزارشگیری و تجزیه و تحلیل داده با قابلیت ادغام با دادههای کلان.
-
اسپلانک (Splunk):
- یک پلتفرم تحلیل لاگ و دادههای عظیم با قابلیت جستجو و مانیتورینگ.
ابزارهای تحلیل کلان داده
ابزارهای متعددی برای تحلیل دادههای حجیم (کلان داده) در حال حاضر در دسترس هستند. در این بخش، به بررسی سه جنبه اساسی، یعنی نگاشت-کاهش، آپاچی اسپارک، و استورم، در زمینه تحلیل دادههای حجیم پرداخته خواهد شد. اغلب تمرکز ابزارهای کنونی بر روی پردازش دستهای (batch processing)، پردازش جریان (stream processing) و تحلیل تعاملی (interactive analysis) قرار دارد.
بسیاری از ابزارهای پردازش دسته برپایه زیرساخت آپاچی هادوپ مانند آپاچی ماهوت و دریاد وجود دارند. برنامههای تحلیل دادههای جریانی معمولاً برای تحلیلهای زمان واقعی مورد استفاده قرار میگیرند، که استورم و اسپلانک به عنوان نمونههایی از پلتفرمهای تحلیل جریان دادهها ذکر میشوند.
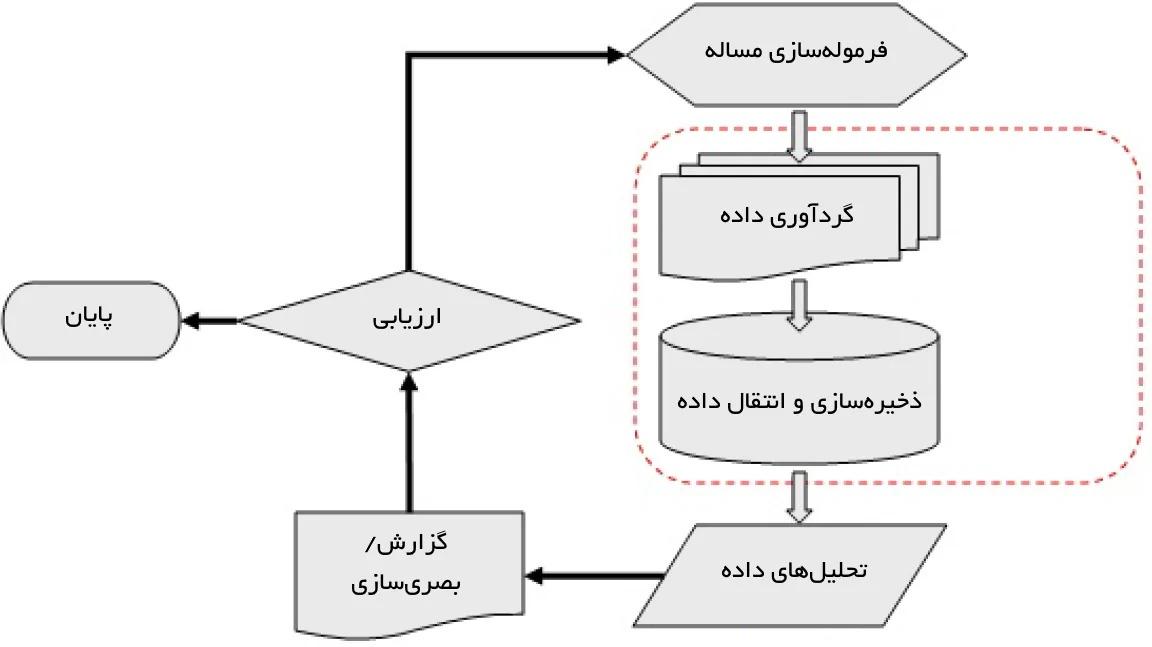
پروسه تحلیل تعاملی به کاربران امکان تعامل مستقیم در زمان واقعی را برای انجام تحلیلهای خود فراهم میکند. به عنوان مثال، درمل و آپاچی دریل به عنوان پلتفرمهای کلانداده تحتاپشیری هستند که از تحلیلهای تعاملی پشتیبانی میکنند. این ابزارها به پژوهشگران در توسعه پروژههای کلانداده کمک میکنند. جریان کار معمول برای پروژههای کلانداده توسط هانگ و همکاران در مقالهای با عنوان "فرصتها و چالشهای پردازش کلانداده در علوم سلامت" تشریح شده است. روند مربوط به جریانهای کاری در پروژههای کلانداده نیز در شکل زیر آمده است.
آپاچی هادوپ و نگاشت کاهش
یکی از پرکاربردترین پلتفرمهای نرمافزاری برای انجام تحلیلهای کلانداده، «آپاچی هادوپ» (Apache Hadoop) به همراه الگوریتم نگاشت کاهش (MapReduce) استفاده میشود. این پلتفرم شامل چندین کامپوننت اصلی مانند کرنل هادوپ، الگوریتم نگاشت کاهش، سیستم فایل توزیع شده هادوپ (Hadoop Distributed File System | HDFS) و ابزارهایی مانند «آپاچی هایو» (Apache Hive) میباشد.
نگاشت کاهش یک مدل برنامهنویسی است که برای پردازش دادههای حجیم بر مبنای روش «تقسیم و حل» (divide and conquer) پیادهسازی شده است. این روش در دو گام اصلی به نامهای نگاشت (Map) و کاهش (Reduce) قرار دارد. هادوپ بر روی دو نوع گره، یعنی گره اصلی (master node) و گره کارگر (worker node) عمل میکند.
در این فرآیند، گره اصلی ورودی را به زیرمسائل کوچکتر تقسیم میکند و سپس در گام نگاشت، این زیرمسائل را به گرههای کارگر توزیع میکند. در نهایت، گره اصلی خروجیها را در گام کاهش ترکیب میکند. تحلیلگران کلانداده از هادوپ و الگوریتم نگاشت کاهش به عنوان یک چارچوب نرمافزاری قدرتمند برای حل مسائل کلانداده استفاده میکنند. این چارچوب به دلیل قابلیت ذخیرهسازی دارای تحمل خطا و پردازش داده با توان بالا، در تحلیل و مدیریت دادههای حجیم بسیار موثر است.
آپاچی ماهوت
آپاچی ماهوت قصد فراهم کردن روشهای یادگیری ماشین مقیاسپذیر و تجاری برای نرمافزارهای تحلیل داده هوشمند و بزرگ مقیاس را دارد. الگوریتمهای اصلی ماهوت شامل خوشهبندی، دستهبندی، کاوش الگو، رگرسیون، کاهش ابعاد، الگوریتمهای تکاملی و فیلتر مشارکتی مبتنی بر دسته بر فراز پلتفرم هادوپ از طریق چارچوب نگاشت کاهش میشوند. هدف ماهوت ساخت یک جامعه فعال، پاسخگو و متنوع به منظور تسهیل گفتوگوها در پروژهها و بررسیهای موردی بالقوه است. آپاچی ماهوت با هدف فراهم کردن ابزاری به منظور حل چالشهای کلانداده ایجاد شده است. از جمله شرکتهایی که از الگوریتمهای مقیاسپذیر یادگیری ماشین استفاده کردهاند میتوان به گوگل، IBM، آمازون، یاهو و فیسبوک اشاره کرد.
آپاچی اسپارک
آپاچی اسپارک یک چارچوب پردازش کلانداده «متنباز» (open source) است که به منظور انجام پردازش سریع و تحلیلهای پیچیده مورد استفاده قرار میگیرد. این برنامه طی سال ۲۰۰۹ در UC Berkeleys AMPLab ساخته شده و استفاده از آن آسان است.
آپاچی اسپارک به عنوان یک پروژه آپاچی در سال ۲۰۱۰ متنباز شد. اسپارک این امکان را برای کاربران فراهم میکند تا برنامههای خود را به زبانهای جاوا، اسکالا یا پایتون بنویسند. اسپارک علاوه بر الگوریتم نگاشت کاهش، از کوئریهای SQL، جریان داده، یادگیری ماشین و پردازش دادههای گراف نیز پشتیبانی میکند. این چارچوب بر فراز زیرساخت سیستم فایل توزیع شده هادوپ (HDFS) به منظور فراهم کردن عملکردهای بهبودیافته و اضافی اجرا میشود.
اسپارک شامل مولفههایی است که برای مثال میتوان به برنامه راهانداز، مدیر خوشه و گرههای کارگر اشاره کرد. مدیر خوشه کار تخصیص منابع را انجام میدهد تا پردازش داده به شکل مجموعهای از وظایف انجام شود. هر برنامه شامل مجموعهای از پردازشها است که به آنها اجراکنندگان گفته میشود و مسئول اجرای هر وظیفهای هستند. مزیت اصلی آپاچی اسپارک آن است که از استقرار برنامههای اسپارک در خوشه هادوپ موجود پشتیبانی میکند. شکل ۶ نمودار معماری آپاچی اسپارک را به تصویر میکشد. ویژگیهای متنوع آپاچی اسپارک در شکل زیر نمایش داده شدهاند.
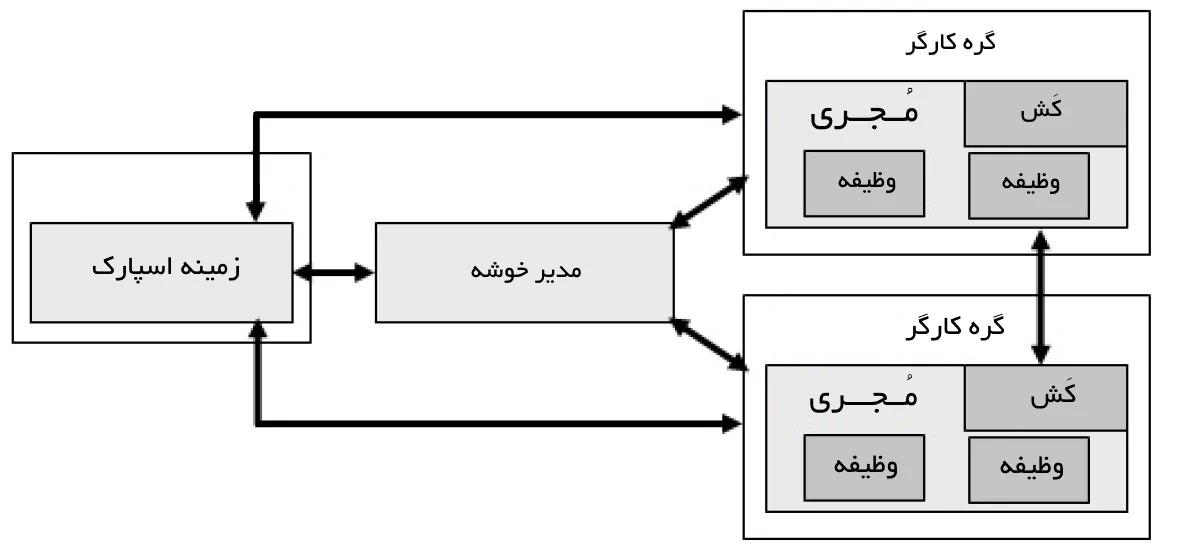
تمرکز اصلی اسپارک بر مجموعه دادههای توزیع شده انعطافپذیر (RDD | Resilient Distributed Datasets) است که دادهها را در حافظه ذخیر کرده و تحملپذیری خطا را بدون تکرار فراهم میکند. همچنین، از رایانش بازگشتی پشتیبانی کرده، و سرعت و کاربردپذیری را بهبود میبخشد. مزیت اصلی اسپارک آن است که علاوه بر نگاشتکاهش، از جریانهای داده، یادگیری ماشین و الگوریتمهای گراف نیز پشتیبانی میکند.
دیگر مزیت این چارچوب آن است که میتواند برنامههای نوشته شده به زبانهای گوناگون شامل جاوا، R، پایتون و اسکالا را اجرا کند. این کتابخانههای استاندارد بهرهوری توسعهدهنده را افزایش داده و میتوانند به صورت یکپارچه ترکیب شوند تا جریانهای کاری پیچیدهای را بسازند.
اسپارک به اجرای یک برنامه در خوشه هادوپ، بالغ بر صد بار سریعتر در حافظه و ده بار سریعتر هنگام اجرا روی دیسک کمک میکند. این کار به دلیل کاهش خواندن و نوشتنها روی حافظه امکانپذیر است. اسپارک به زبان برنامهنویسی اسکالا نوشته شده و روی ماشین مجازی جاوا (JVM) اجرا میشود. همچنین، از جاوا، پایتون و R برای توسعه برنامههای کاربردی با استفاده از اسپارک پشتیبانی میکند.
استورم (Storm)
استورم یک سیستم محاسباتی زمان واقعی توزیع شده و دارای تحملپذیری خطا برای پردازش جریانهای داده است. این سیستم برخلاف هادوپ که برای پردازش دستهای طراحی شده، به منظور انجام پردازش زمان واقعی ساخته شده است. علاوه بر این، راهاندازی و اجرای آن آسان است. استورم، مقیاسپذیر و دارای تحملپذیری در برابر خطا به منظور فراهم کردن کارایی رقابتی است. کاربران خوشه استورم توپولوژیهای گوناگونی را برای وظایف استورم گوناگون اجرا میکنند، در حالیکه پلتفرم هادوپ الگوریتم نگاشت کاهش را برای برنامههای متناظر اجرا میکند.
تفاوتهایی بین کارها و توپولوژیهای نگاشت کاهش وجود دارد. تفاوت اساسی آن است که کار نگاشت کاهش سرانجام به پایان میرسد، در حالیکه یک فرآیند توپولوژی در کلیه زمانها یا دستکم تا زمانی که کاربر آن را متوقف کند پیغام میدهد وشامل دو نوع از خوشهها مانند گره اصلی و کارگر است. گره اصلی و کارگر دو نوع از نقشها مانند nimbus و سرپرست را ایجاد میکنند. دو نقش دارای کارکردهای مشابهی مطابق با jobtracker و tasktracker از چارچوب نگاشت کاهش هستند.
Nimbus مسئولیت توزیع کد در خوشه استورم، برنامهریزی و تخصیص وظایف به گرههای کارگر و نظارت بر کل سیستم را بر عهده دارد. سرپرست، وظایفی که به وسیله nimbus به او تخصیص داده شده را اجرا میکند. علاوه بر این، فرآیندها را در صورت لزوم بر اساس دستورالعمل nimbus آغاز و پایان میبخشد. کل فناوری محاسباتی به تعدادی فرآیند کارگر تقسیمبندی و توزیع شدهاند و هر فرآیند کارگر بخشی از توپولوژی را پیادهسازی میکند.
آپاچی دریل (Apache Drill)
آپاچی دریل، دیگر سیستم توزیع شده برای تحلیلهای تعاملی کلانداده (مِهداده) است. این روش دارای انعطافپذیری بیشتری برای پشتیبانی از بسیاری زبانهای کوئری، فرمتهای داده و منابع داده است. همچنین، این سیستم به طور ویژه برای بهرهبرداری از دادههای تو در تو طراحی شده است و دارای این هدف است که روی ۱۰۰۰۰ سرور یا تعداد بیشتری مقیاس بپذیرد و به ظرفیتت لازم برای پردازش پتابایتها داده و تریلیونها رکورد در چند ثانیه برسد.
Drill از سیستم فایل توزیع شده هادوپ (HDFS) برای ذخیرهسازی و نگاشت کاهش برای انجام تحلیل دستهای استفاده میکند.
دریاد (Dryad)
Dryad دیگر مدل برنامهنویسی مشهود برای پیادهسازی برنامههای موازی و توزیع شده برای مدیریت مبانی زمینهها در گرافهای جریان داده است. این مدل شامل خوشهای از گرههای کامپیوتری میشود و کاربر از منابع یک خوشه کامپیوتر برای اجرای برنامهها به شیوه توزیع شده استفاده میکند. در واقع، یک کاربر Dryad از هزاران ماشین که هر یک چندین هسته یا پردازنده دارند بهرهمند میشود.
مزیت اصلی این مدل آن است که کاربر نیازی به دانستن همه چیز درباره «برنامهنویسی همروند» (concurrent programming) ندارد. یک برنامه Dryad روی یک گراف جهتدار محاسباتی اجرا میشود که از راسهای محاسباتی و کانالهای ارتباطی تشکیل شده است. بنابراین، dryad گستره وسیعی از کارکردها شامل تولید گراف کار (job graph)، برنامهریزی ماشینها برای فرآیندهای موجود، مدیریت شکست انتقال (transition failure handling) در خوشه، مجموعهای از معیارهای کارایی و بصریسازی کار را فراهم میکند.
جابرسافت (Jaspersoft)
بسته Jaspersoft یک نرمافزار متنباز است که گزارشهایی را از ستونهای پایگاه داده تولید میکند. این بسته یک سکوی مقیاسپذیر تحلیل کلانداده (مِهداده) محسوب میشود و دارای ظرفیت بصریسازی سریع دادهها روی پلتفرمهای ذخیرهسازی محبوب مانند MangoDB، «کاساندرا» (Cassandra)، «ردیس» (Redis) و دیگر موارد است.
یک ویژگی مهم Jaspersoft آن است که کلانداده را به سرعت و بدون استخراج، تبدیل و بارگذاری (ETL) مورد اکتشاف قرار میدهد. علاوه بر این، توانایی ساخت گزارشها و دشبوردهای تعاملی زبان نشانهگذاری ابرمتنی (Hypertext Markup Language | HTML) را به طور مستقیم از انبار کلانداده بدون نیاز به ETL دارد. این گزارشهای تولید شده را میتوان با هر کسی از درون یا بیرون سازمان به اشتراک گذاشت.
اسپلانک (Splunk)
در سالهای اخیر دادههای بسیاری از طریق ماشینها در کسبوکارها و صنایع تولید شده است. Splunk یک پلتفرم زمان واقعی و هوشمند توسعه داده شده برای بهرهبرداری از کلاندادههای تولید شده توسط ماشینها است. این پلتفرم بسیاری از فناوریهای ابری موجود و کلانداده (مِهداده) را ترکیب کرده است و به نوبه خود به کاربران جهت جستوجو، نظارت و تحلیل دادههای تولید شده توسط ماشین از طریق یک رابط وب کمک میکند.
نتایج به شیوهای نوآورانه مانند گرافها، گزارشها و هشدارها نمایش داده میشوند. Splunk از دیگر ابزارهای پردازش جریان موجود متفاوت است. از جمله تفاوتهای آن با دیگر ابزارهای موجود میتوان به اندیسگذاری دادههای ساختاریافته و ساختارنیافته تولید شده توسط ماشینها، جستوجوی زمان واقعی، گزارش نتایج تحلیلی و دشبوردها اشاره کرد. مهمترین هدف Splunk فراهم کردن معیارهایی برای کاربردهای گوناگون، تشخیص خطا برای زیرساختهای فناوری اطلاعات، سیستم و پشتیبانی هوشمند برای عملیات کسبوکارها است.
پیشنهادات پژوهش
انتظار میرود حجم دادههای گردآوری شده از حوزههای گوناگون در سراسر جهان هر دو سال دو برابر شود (با افزایش نرخ تولید دادهها، این نسبت در حال تغییر است). این دادهها هیچ کاربردی ندارند مگر اینکه به منظور کسب اطلاعات مفید مورد تحلیل قرار بگیرند.
این امر توسعه روشهایی برای تسهیل تحلیلهای کلانداده (تحلیلهای مِهداده) را الزامی میکند. تبدیل دادهها به دانش با پردازشهای دارای کارایی و مقیاس بالا امری دشوار است که انتظار میرود با بهرهگیری از پردازش موازی و پردازش توزیع شده در معماریهای کامپیوتر ویژه دادهکاوی در حال ظهور تسهیل شود.
علاوه بر این، این دادهها ممکن است در برگیرنده عدم قطعیت در بسیاری از اشکال گوناگون باشند. مدلهای متفاوت بسیاری مانند مجموعههای فازی، مجموعههای خام، مجموعههای نرم، شبکههای عصبی و مدلهای ترکیبی با ترکیب یک یا چند نوع از این مدلها برای ارائه دانش و تحلیل دادهها بسیار موثر هستند. اغلب اوقات، ابعاد کلاندادهها به منظور دربرگیری مشخصههای اصلی لازم برای یک پژوهش خاص کاهش پیدا میکنند. بنابراین، روشهایی برای کاهش این ابعاد ارائه شده است.
دادهها اغلب دارای مقادیر از دست رفته (missing values) هستند. این مقادیر باید به نوعی تولید شده و یا تاپلهای حاوی مقدار از دست رفته حذف شوند. مهمتر آنکه، این چالشها ممکن است کارایی، تاثیرگذاری و مقیاسپذیری یک سیستم محاسباتی فشرده اطلاعات را با مشکل مواجه کند. از این رو، یکی از زمینههای مهم نیازمند پژوهش در حوزه کلان داده چگونگی ثبت و دسترسی موثر به دادهها است. پردازش سریع دادهها همگام با کسب کارایی و بازده بالا برای کاربردهای آتی مساله دیگری است.
علاوه بر این، برنامهنویسی برای تحلیلهای کلانداده چالش مهمی محسوب میشود. تشریح نیازمندیهای دسترسی به داده در برنامهها و طراحی انتزاعی زبان برنامهنویسی برای بهرهبرداری از پردازش موازی دیگر نیاز مهم این حوزه است. مفاهیم و ابزارهای یادگیری ماشین در میان پژوهشگران برای تسهیل نتایج معنادار از این مفاهیم نیز مهم هستند. پژوهشگران حوزه یادگیری ماشین بر پیشپردازش دادهها، پیادهسازی الگوریتمها و بهینهسازی آنها متمرکز شدهاند.
بسیاری از ابزارهای یادگیری ماشین برای استفاده در زمینه کلاندادهها نیازمند تغییرات قابل توجهی هستند. ابزارهای موثرتری را میتوان برای سر و کار داشتن با مسائلی که از کلان داده نشات میگیرند ارائه کرد. این ابزارها باید برای مدیریت دادههای دارای نویز و نامتوازن، عدم قطعیت و ناسازگاری و مقادیر از دست رفته ساخته و توسعه داده شوند.
نتیجهگیری
در دههی اخیر، حجم دادهها به سرعت افزایش یافته است و تحلیل این دادهها برای انسانها چالشهای زیادی ایجاد کرده است. در این مقاله، ابزارهای موردنیاز برای تحلیل دادههای حجیم به بررسی پرداختهاند. بر اساس توضیحات ارائه شده، مشخص است که هر یک از این ابزارها بر تمرکز خاصی در زمینههای مختلف متمرکز شدهاند. برخی از این ابزارها برای پردازش دستهای و برخی دیگر برای تحلیلهای زمان واقعی بهکار میروند.
هر پلتفرم داده حجیم نیز دارای ویژگیها و عملکردهای خود است. از روشهای متنوعی برای تحلیل داده حجیم (Big Data) استفاده میشود، از جمله تحلیلهای آماری، یادگیری ماشین، دادهکاوی، تحلیل هوشمند، رایانش ابری، رایانش کوانتومی و پردازش جریان داده.
این پویش تنوع بخشهای مختلف تجزیه و تحلیل داده حجیم را نمایان میکند و از آنجا که ابزارها به تخصصهای خاصی متمرکز شدهاند، میتوانند نیازهای مختلف کاربران را برآورده سازند. این ابزارها از تحلیلهای آماری گرفته تا یادگیری ماشین و هوشمندسازی تحلیل داده را فراهم میکنند.
برای ثبت نظر لطفا وارد حساب کاربری شوید
ورود / ثبت نام

{kind=link}